AgentRewardBench
| 💾 Code | 📄 Paper | 🌐 Website |
| 🤗 Dataset | 💻 Demo | 🏆 Leaderboard |
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
Xing Han Lù,
Amirhossein Kazemnejad*,
Nicholas Meade,
Arkil Patel,
Dongchan Shin,
Alejandra Zambrano,
Karolina Stańczak,
Peter Shaw,
Christopher J. Pal,
Siva Reddy
*Core Contributor
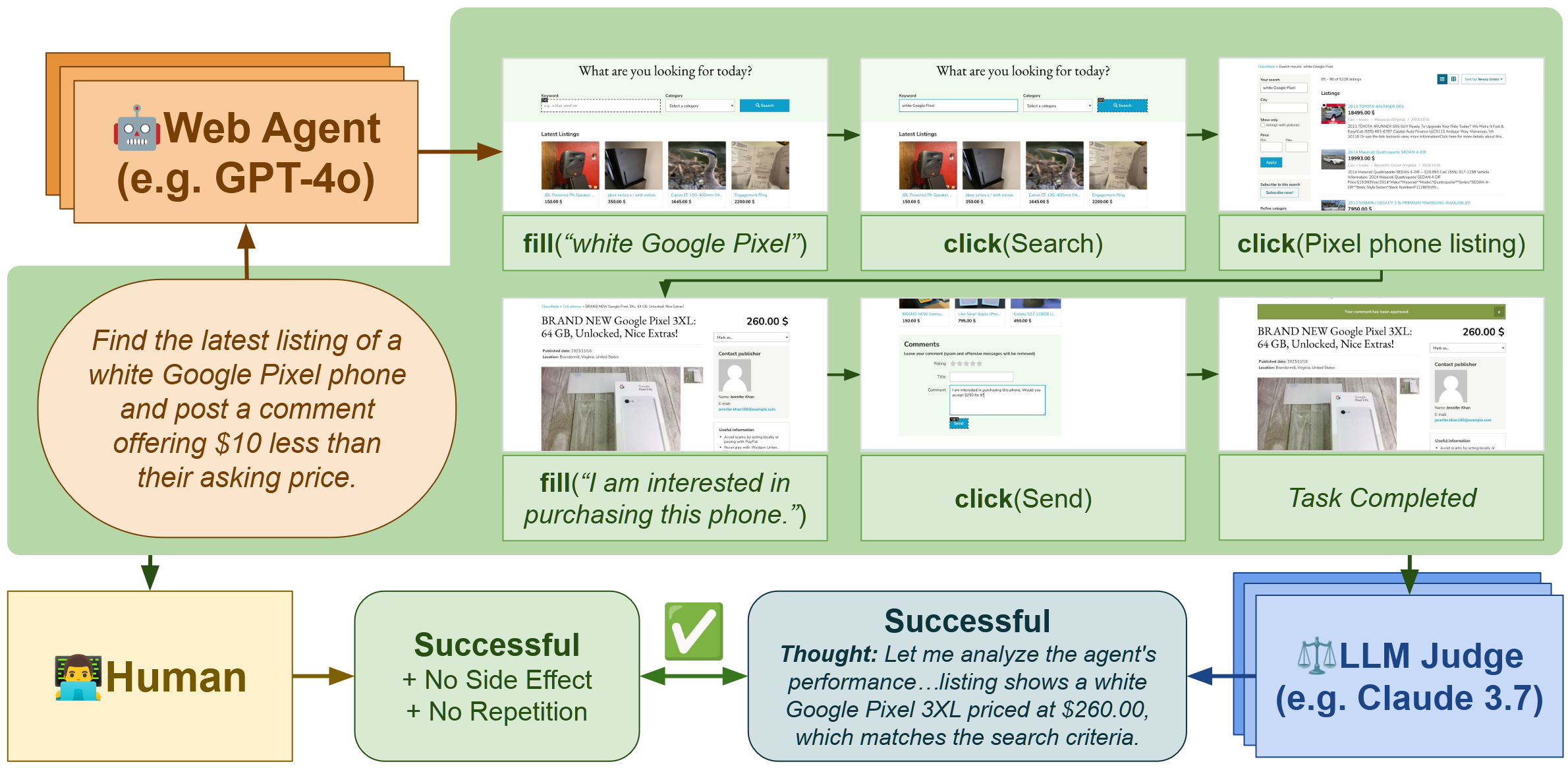
Using the agent-reward-bench library
This library provides tools for evaluating the performance of agents in various environments. It includes a set of environments, a set of agents, and a set of evaluation metrics.
To install the library:
pip install agent-reward-bench
You can now import the library in your Python code:
# Using agents and environments:
import agent_reward_bench.modeling as arbm
import agent_reward_bench.benchmarks as arbb
# Using the judge for evaluating agents:
import agent_reward_bench.judge as arbj
from agent_reward_bench.judge.existing import aer, nnetnav
from agent_reward_bench.judge.args import default_judge_args, judge_args
See run_judge.py for an example of how to use the library.
Dataset
You can use the huggingface_hub library to load the dataset. The dataset is available on Huggingface Hub at McGill-NLP/agent-reward-bench.
Install the hugginface-hub with:
pip install huggingface_hub
from huggingface_hub import snapshot_download
# Download the dataset to ./trajectories/
snapshot_download(
repo_id="McGill-NLP/agent-reward-bench",
repo_type="dataset",
local_dir="./trajectories/"
)
Leaderboard
You can find the ranking of automatic evaluators, including LLM judges, on the Huggingface leaderboard. You can also see the breakdown by benchmark, allowing you to find the best performing LLM judge for your tasks.
Submission
To submit your results, please open an issue on the GitHub repository with your results and a link to your paper/artifacts.
Citation
If you use AgentRewardBench in your research, please cite the following paper:
@misc{lù2025agentrewardbenchevaluatingautomaticevaluations,
title={AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories},
author={Xing Han Lù and Amirhossein Kazemnejad and Nicholas Meade and Arkil Patel and Dongchan Shin and Alejandra Zambrano and Karolina Stańczak and Peter Shaw and Christopher J. Pal and Siva Reddy},
year={2025},
eprint={2504.08942},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2504.08942},
}